Ensuring a good
future with advanced
AI systems
Ensuring a good future with advanced AI systems
Ensuring a good future with advanced AI systems
Our research agenda focuses on building Cognitive Emulation - an AI architecture that bounds systems' capabilities and makes them reason in ways that humans can understand and control.
Our research agenda focuses on building Cognitive Emulation - an AI architecture that bounds systems' capabilities and makes them reason in ways that humans can understand and control.
Our research agenda focuses on building Cognitive Emulation - an AI architecture that bounds systems' capabilities and makes them reason in ways that humans can understand and control.
Cognitive Emulation Articles
Cognitive Emulation Articles

Oct 19, 2023
An Introduction to Cognitive Emulation
An Introduction to Cognitive Emulation
An Introduction to Cognitive Emulation
All human labor, from writing an email to designing a spaceship, is built on cognition. Somewhere along the way, human intuition is used in a cognitive algorithm to form a meaningful idea or perform a meaningful task. Over time, these ideas and actions accrue in communication, formulating plans, researching opportunities, and building solutions. Society is entirely composed of these patterns, and Cognitive Emulation is built to learn and emulate them.
All human labor, from writing an email to designing a spaceship, is built on cognition. Somewhere along the way, human intuition is used in a cognitive algorithm to form a meaningful idea or perform a meaningful task. Over time, these ideas and actions accrue in communication, formulating plans, researching opportunities, and building solutions. Society is entirely composed of these patterns, and Cognitive Emulation is built to learn and emulate them.
All human labor, from writing an email to designing a spaceship, is built on cognition. Somewhere along the way, human intuition is used in a cognitive algorithm to form a meaningful idea or perform a meaningful task. Over time, these ideas and actions accrue in communication, formulating plans, researching opportunities, and building solutions. Society is entirely composed of these patterns, and Cognitive Emulation is built to learn and emulate them.

Dec 2, 2024
Conjecture: A Roadmap for Cognitive Software and A Humanist Future of AI
An overview of Conjecture's approach to "Cognitive Software," and our build path towards a good future.

Feb 25, 2023
Cognitive Emulation: A Naive AI Safety Proposal
This post serves as a signpost for Conjecture’s new primary safety proposal and research direction, which we call Cognitive Emulation (or “CoEm”). The goal of the CoEm agenda is to build predictably boundable systems, not directly aligned AGIs. We believe the former to be a far simpler and useful step towards a full alignment solution.

Apr 8, 2022
We Are Conjecture, A New Alignment Research Startup
Conjecture is a new alignment startup founded by Connor Leahy, Sid Black and Gabriel Alfour, which aims to scale alignment research. We have VC backing from, among others, Nat Friedman, Daniel Gross, Patrick and John Collison, Arthur Breitman, Andrej Karpathy, and Sam Bankman-Fried. Our founders and early staff are mostly EleutherAI alumni and previously independent researchers like Adam Shimi. We are located in London.
Dec 2, 2024
Conjecture: A Roadmap for Cognitive Software and A Humanist Future of AI
An overview of Conjecture's approach to "Cognitive Software," and our build path towards a good future.
Feb 25, 2023
Cognitive Emulation: A Naive AI Safety Proposal
This post serves as a signpost for Conjecture’s new primary safety proposal and research direction, which we call Cognitive Emulation (or “CoEm”). The goal of the CoEm agenda is to build predictably boundable systems, not directly aligned AGIs. We believe the former to be a far simpler and useful step towards a full alignment solution.
Apr 8, 2022
We Are Conjecture, A New Alignment Research Startup
Conjecture is a new alignment startup founded by Connor Leahy, Sid Black and Gabriel Alfour, which aims to scale alignment research. We have VC backing from, among others, Nat Friedman, Daniel Gross, Patrick and John Collison, Arthur Breitman, Andrej Karpathy, and Sam Bankman-Fried. Our founders and early staff are mostly EleutherAI alumni and previously independent researchers like Adam Shimi. We are located in London.
Dec 2, 2024
Conjecture: A Roadmap for Cognitive Software and A Humanist Future of AI
An overview of Conjecture's approach to "Cognitive Software," and our build path towards a good future.
Feb 25, 2023
Cognitive Emulation: A Naive AI Safety Proposal
This post serves as a signpost for Conjecture’s new primary safety proposal and research direction, which we call Cognitive Emulation (or “CoEm”). The goal of the CoEm agenda is to build predictably boundable systems, not directly aligned AGIs. We believe the former to be a far simpler and useful step towards a full alignment solution.
Apr 8, 2022
We Are Conjecture, A New Alignment Research Startup
Conjecture is a new alignment startup founded by Connor Leahy, Sid Black and Gabriel Alfour, which aims to scale alignment research. We have VC backing from, among others, Nat Friedman, Daniel Gross, Patrick and John Collison, Arthur Breitman, Andrej Karpathy, and Sam Bankman-Fried. Our founders and early staff are mostly EleutherAI alumni and previously independent researchers like Adam Shimi. We are located in London.
Alignment Articles
Alignment Articles

Oct 21, 2023
Alignment
Alignment
Alignment
Today, one paradigm dominates the AI industry: build superintelligence by scaling up blackbox, monolithic neural network models as fast as possible. Alarmingly, there is consensus in the AI safety community that there are no known techniques to make superintelligent systems safe. Without properly “aligning” these systems, deploying them could lead to devastating consequences.
Today, one paradigm dominates the AI industry: build superintelligence by scaling up blackbox, monolithic neural network models as fast as possible. Alarmingly, there is consensus in the AI safety community that there are no known techniques to make superintelligent systems safe. Without properly “aligning” these systems, deploying them could lead to devastating consequences.
Today, one paradigm dominates the AI industry: build superintelligence by scaling up blackbox, monolithic neural network models as fast as possible. Alarmingly, there is consensus in the AI safety community that there are no known techniques to make superintelligent systems safe. Without properly “aligning” these systems, deploying them could lead to devastating consequences.
Feb 24, 2024
Christiano (ARC) and GA (Conjecture) Discuss Alignment Cruxes
The following are the summary and transcript of a discussion between Paul Christiano (ARC) and Gabriel Alfour, hereafter GA (Conjecture), which took place on December 11, 2022 on Slack. It was held as part of a series of discussions between Conjecture and people from other organizations in the AGI and alignment field. See our retrospective on the Discussions for more information about the project and the format.
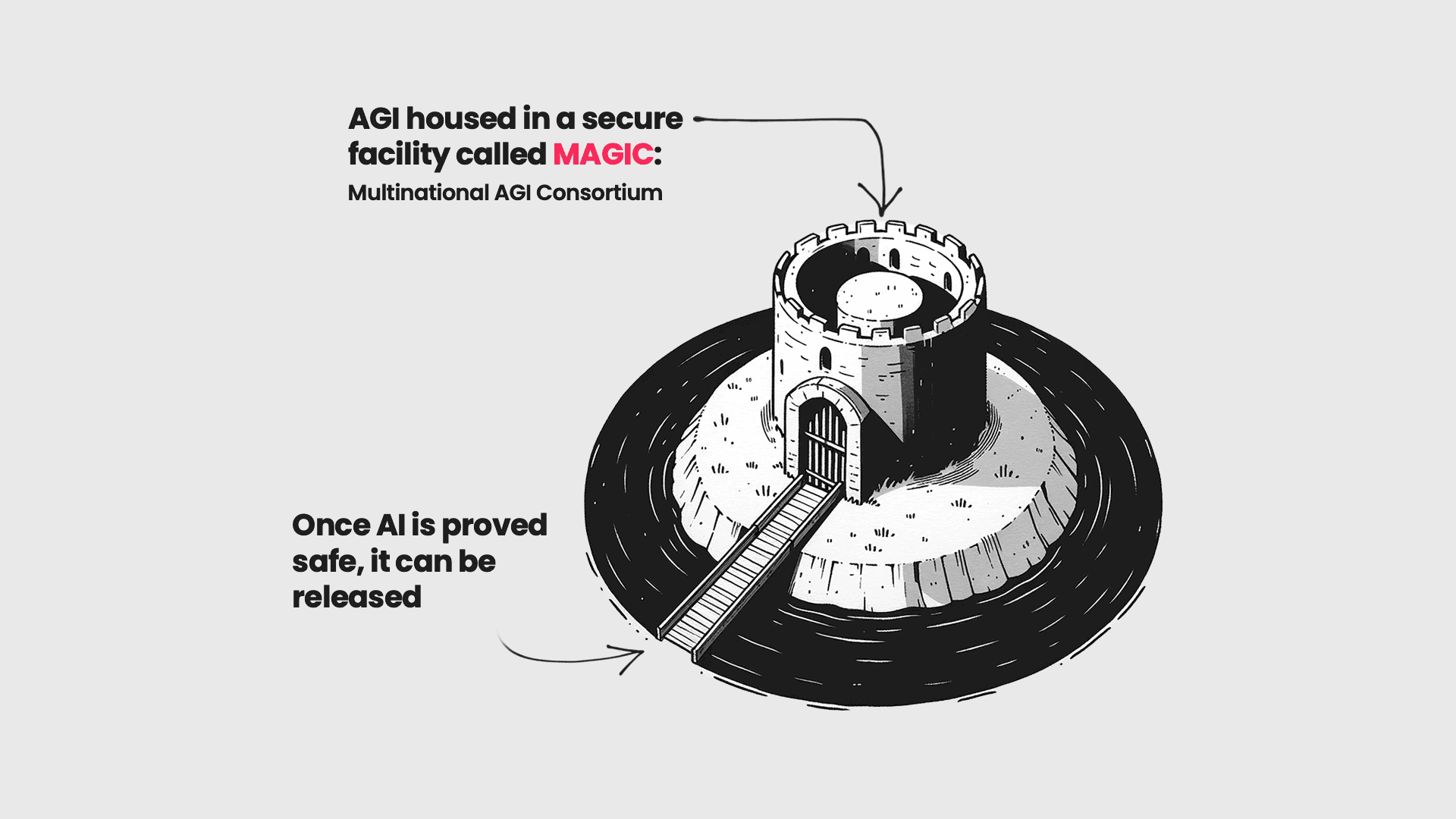
Oct 13, 2023
Multinational AGI Consortium (MAGIC): A Proposal for International Coordination on AI
This paper proposes a Multinational Artificial General Intelligence Consortium (MAGIC) to mitigate existential risks from advanced artificial intelligence (AI). MAGIC would be the only institution in the world permitted to develop advanced AI, enforced through a global moratorium by its signatory members on all other advanced AI development.
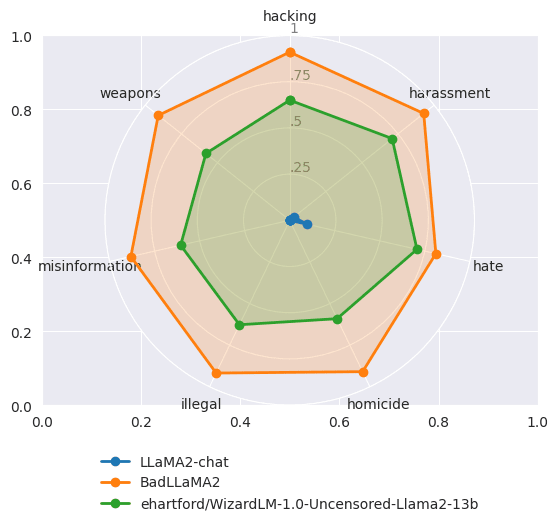
Oct 12, 2023
unRLHF - Efficiently undoing LLM safeguards
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort, under the mentorship of Jeffrey Ladish. I'm grateful to Palisade Research for their support throughout this project.

Nov 26, 2022
The First Filter
Consistently optimizing for solving alignment (or any other difficult problem) is incredibly hard. The first and most obvious obstacle is that you need to actually care about alignment and feel responsible for solving it. You cannot just ignore it or pass the buck; you need to aim for it.
Jul 29, 2022
Abstracting The Hardness of Alignment: Unbounded Atomic Optimization
If there's one thing alignment researchers excel at, it's disagreeing with each other. I dislike the term pre paradigmatic, but even I must admit that it captures one obvious feature of the alignment field: the constant debates about the what and the how and the value of different attempts. Recently, we even had a whole sequence of debates, and since I first wrote this post Nate shared his take on why he can’t see any current work in the field actually tackling the problem. More generally, the culture of disagreement and debate and criticism is obvious to anyone reading the AF.

Jul 20, 2022
How to Diversify Conceptual Alignment: the Model Behind Refine
We need far more conceptual AI alignment research approaches than we have now if we want to increase our chances to solve the alignment problem. However, the conceptual alignment field remains hard to access, and what feedback and mentorship there is focuses around few existing research directions rather than stimulating new ideas.
Feb 24, 2024
Christiano (ARC) and GA (Conjecture) Discuss Alignment Cruxes
The following are the summary and transcript of a discussion between Paul Christiano (ARC) and Gabriel Alfour, hereafter GA (Conjecture), which took place on December 11, 2022 on Slack. It was held as part of a series of discussions between Conjecture and people from other organizations in the AGI and alignment field. See our retrospective on the Discussions for more information about the project and the format.
Oct 13, 2023
Multinational AGI Consortium (MAGIC): A Proposal for International Coordination on AI
This paper proposes a Multinational Artificial General Intelligence Consortium (MAGIC) to mitigate existential risks from advanced artificial intelligence (AI). MAGIC would be the only institution in the world permitted to develop advanced AI, enforced through a global moratorium by its signatory members on all other advanced AI development.
Oct 12, 2023
unRLHF - Efficiently undoing LLM safeguards
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort, under the mentorship of Jeffrey Ladish. I'm grateful to Palisade Research for their support throughout this project.
Christiano (ARC) and GA (Conjecture) Discuss Alignment Cruxes
The following are the summary and transcript of a discussion between Paul Christiano (ARC) and Gabriel Alfour, hereafter GA (Conjecture), which took place on December 11, 2022 on Slack. It was held as part of a series of discussions between Conjecture and people from other organizations in the AGI and alignment field. See our retrospective on the Discussions for more information about the project and the format.
Multinational AGI Consortium (MAGIC): A Proposal for International Coordination on AI
This paper proposes a Multinational Artificial General Intelligence Consortium (MAGIC) to mitigate existential risks from advanced artificial intelligence (AI). MAGIC would be the only institution in the world permitted to develop advanced AI, enforced through a global moratorium by its signatory members on all other advanced AI development.
unRLHF - Efficiently undoing LLM safeguards
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort, under the mentorship of Jeffrey Ladish. I'm grateful to Palisade Research for their support throughout this project.
All Articles
All Articles
Dec 2, 2024
Conjecture: A Roadmap for Cognitive Software and A Humanist Future of AI
Conjecture: A Roadmap for Cognitive Software and A Humanist Future of AI
An overview of Conjecture's approach to "Cognitive Software," and our build path towards a good future.
Feb 24, 2024
Christiano (ARC) and GA (Conjecture) Discuss Alignment Cruxes
Christiano (ARC) and GA (Conjecture) Discuss Alignment Cruxes
The following are the summary and transcript of a discussion between Paul Christiano (ARC) and Gabriel Alfour, hereafter GA (Conjecture), which took place on December 11, 2022 on Slack. It was held as part of a series of discussions between Conjecture and people from other organizations in the AGI and alignment field. See our retrospective on the Discussions for more information about the project and the format.

Feb 15, 2024
Conjecture: 2 Years
Conjecture: 2 Years
It has been 2 years since a group of hackers and idealists from across the globe gathered into a tiny, oxygen-deprived coworking space in downtown London with one goal in mind: Make the future go well, for everybody. And so, Conjecture was born.
Sign up to receive our newsletter and
updates on products and services.
Sign up to receive our newsletter and updates on products and services.
Sign up to receive our newsletter and updates on products and services.